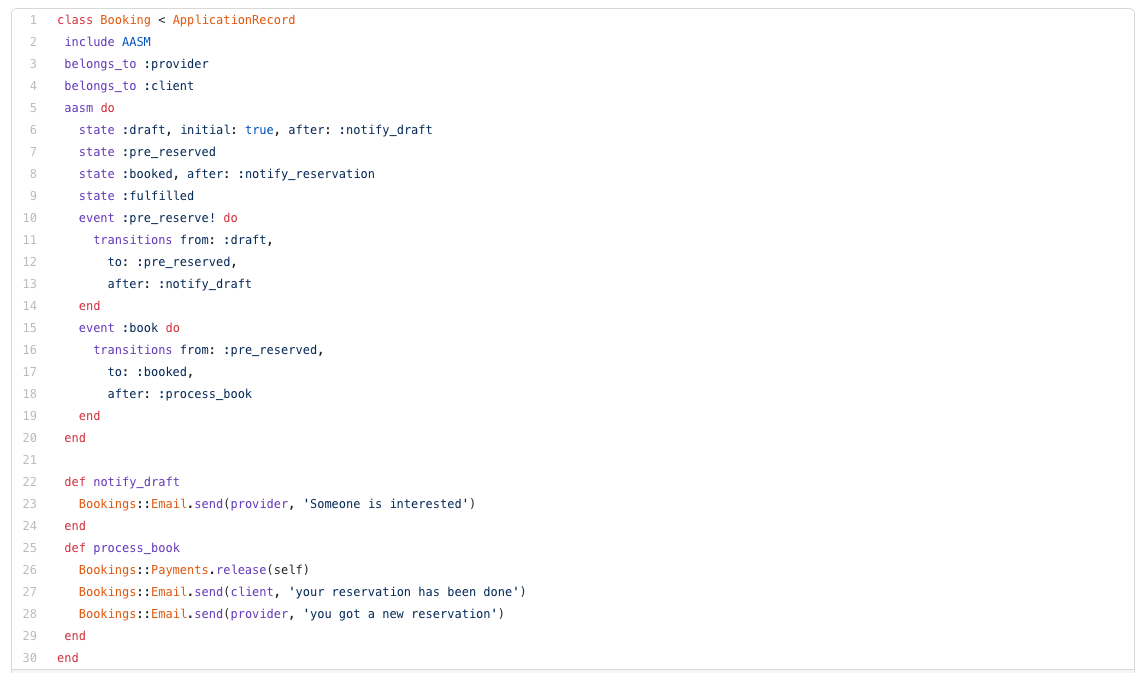
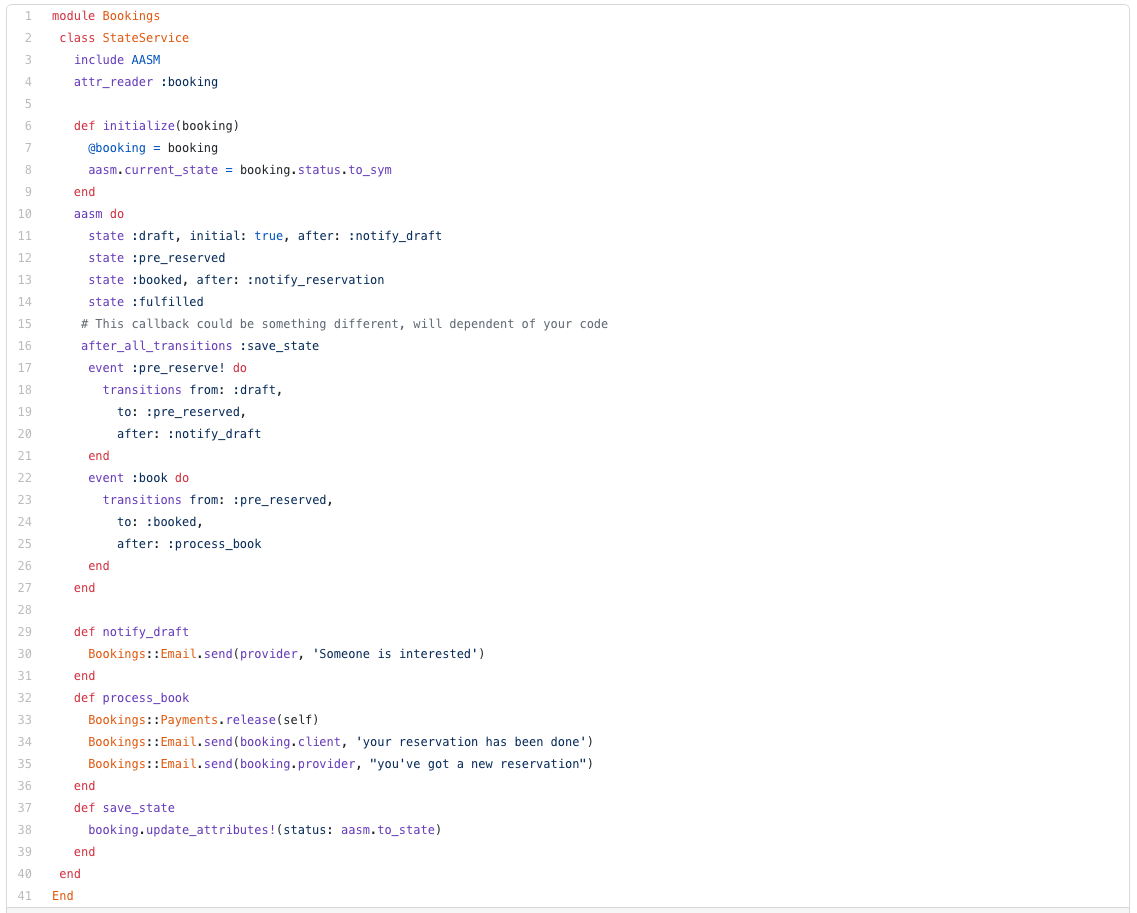
We recently wanted to remove an Amazon S3 bucket where 1,000,000+ files were stored. This bucket also had versioning enabled which means the actual number of files was way bigger. To give us an idea, we dump the file paths to delete: the associated output text was 500MB big.
This task which seems simple at first proved to be quite complicated to handle, mostly because of Amazon own limitations that it would be nice to see addressed.
The first thing we had to do is obviously to disable versioning in the Amazon Web Services console:
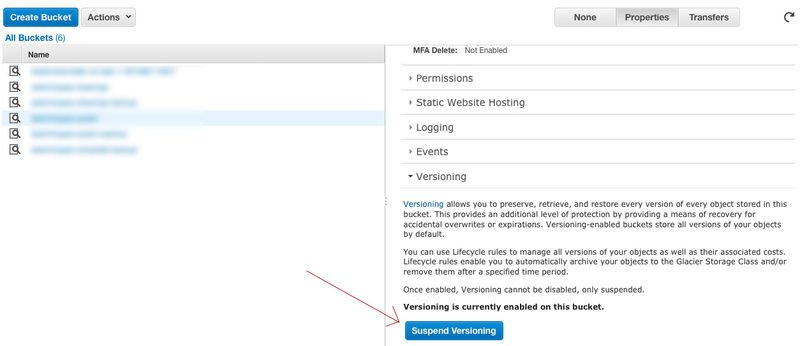
Without this, not only the bucket would not be emptied but some delete markers would be added to the bucket which would make our life even harder.
The first assumption a user has when wanting to delete a S3 bucket is that clicking on Delete Bucket works. But Amazon does not allow to delete a non empty bucket.
Emptying the bucket through the Amazon Console does not work either when the bucket contains more than 10,000 files. And this is where the troubles begin: simply listing the files to delete ends up crashing the most popular S3 tools like s3cmd.
We found some really interesting scripts which are designed to delete both delete markers and all file versions on a S3 bucket. These scripts were indeed deleting the files on our S3 bucket but kept on running after four days in a row.
The main reason for this is that a query is made for each file deletion. We needed to perform some bulk delete instead.
Amazon CLI provides the capacity to delete up to 1000 files using a single HTTP request via the delete-objects command.
We engineered a ruby script which relies on this command to delete our files faster:
Pre-requisites:
To use this script you need to:
- Export your Amazon credentials:
export AWS_ACCESS_KEY_ID=...andexport AWS_SECRET_ACCESS_KEY=... - Have the Amazon CLI installed.
- Have a Ruby interpreter installed.
- Download the above file and make it executable:
chmod +x FILE
Usage:
Simply execute the script like any other programs with the bucket name you would like to empty as the argument.
E.g: Providing the Ruby script was called S3_bucket_cleaner.rb:
./S3_bucket_cleaner.rb BUCKET_NAME
Figures and conclusion:
The above script was able to remove all the files of our S3 bucket in less than 20 min which was good! It would be great if Amazon let people emptying / removing a S3 bucket regardless how full this one is. In the meantime, we are happy to share this script with you today in case you run into a similar scenario.